Answers with Receipts: 5 Frameworks for Governed Multi-Agent Data Analysis

%20(35).png)
Most agent demos look brilliant—right up until a real stakeholder asks a hard question, a data-access policy kicks in, and someone says, "show me how you got that number." That's when cute agent scripts break. Governed agents don't.
This is a field-tested view of what actually works when you move from proof-of-concept agents to production analytics that are safe, explainable, and repeatable. The stack has five jobs:
- Policy before action
- Graph-based planning
- Governed semantics with pushdown access
- Precise retrieval and scoped memory
- Verification with visible reasoning and evaluation

One design choice underpins the rest: a hybrid router (SRL + Text-to-SQL) that is fast when the ask is simple and powerful when the logic is complex—under one policy and semantic contract.
Production reality check: The multi-agent complexity tax

Last year taught a simple lesson: multi-agent orchestration looks elegant on paper and messy in production. Split work across autonomous agents and you invite new failure modes—conflicting assumptions, brittle termination, state drift, and hard-to-explain behavior. Industry data confirms that multi-agent systems consume 15-20x more tokens than single-agent alternatives while 74% of companies struggle to achieve and scale AI value. Teams that began with "let's parallelize everything" converged on a more constrained pattern: centralize context, plan deterministically, and branch only when the benefit is clear.
That's why we run a hybrid router—SRL for fast, governed asks; Text-to-SQL for complex logic—under one policy gate and one semantic contract. It keeps the experience sharp and the audit story clean.
Why "governed agents," not just "agents"?
Enterprises judge analytical agents on four non-negotiables:
- Protect sensitive data by default. Access controls and masking must apply before any tool, model, or query runs—not as a hopeful instruction in a prompt.
- Show your work. Answers must carry context: what was interpreted, which data/definitions were used, and which rules constrained the run.
- Behave consistently irrespective of the module you use, be it dashboards, deep dive insights or search—same policies and definitions.
- Scale without rewrites. New analysis patterns shouldn’t force duplicating business logic across surfaces or teams. Plug every interface into a single semantic/policy layer and push computation to the source, so you can add capability without refactoring three stacks.
Those constraints push you to centralize policy and semantics, plan work explicitly, and make every answer auditable. The hybrid SRL/Text-to-SQL approach is how we meet those constraints without sacrificing capability.
The hybrid router (SRL + Text-to-SQL): Two lanes, one contract
Why two lanes (not many agents). Two well-governed lanes cover the vast majority of analytical asks without the overhead of coordinating many agents. The router's job isn't to be clever; it's to be safe and predictable.
SRL lane (fast & deterministic). For everyday asks that map cleanly to governed metrics, time windows, filters, and breakdowns. Interactive, explorable, and close to the semantic model.
Text-to-SQL lane (power for complex logic). For joins across entities, nested filters, custom windows, "ratio of ratios," and other heavy queries. Generates schema-aware SQL guided by governed context; returns precomputed results when full interactivity isn't safe.
Routing decision. A small classifier picks the lane. It looks at:
- Query complexity: joins, nested logic, multiple metrics/dimensions.
- Semantic confidence: how sure we are about metric/dimension meanings.
- Safety constraints: row limits, presence of sensitive entities/columns.
- Performance budgets: target latency and cost.
It then chooses SRL or Text-to-SQL and logs the reason in the answer's audit trail. Organizations report 5-15% latency reduction and 10-20% reduction in costly model invocations through dynamic routing strategies like this.
One enforcement point. No matter the lane, the plan runs through a governed query layer. That's where row-level filters and PII masking are applied at the source, and where the run is audited. A single policy gate ensures one version of truth across all requests.
Framework #1 — Policy before action (the pre-execution gate)
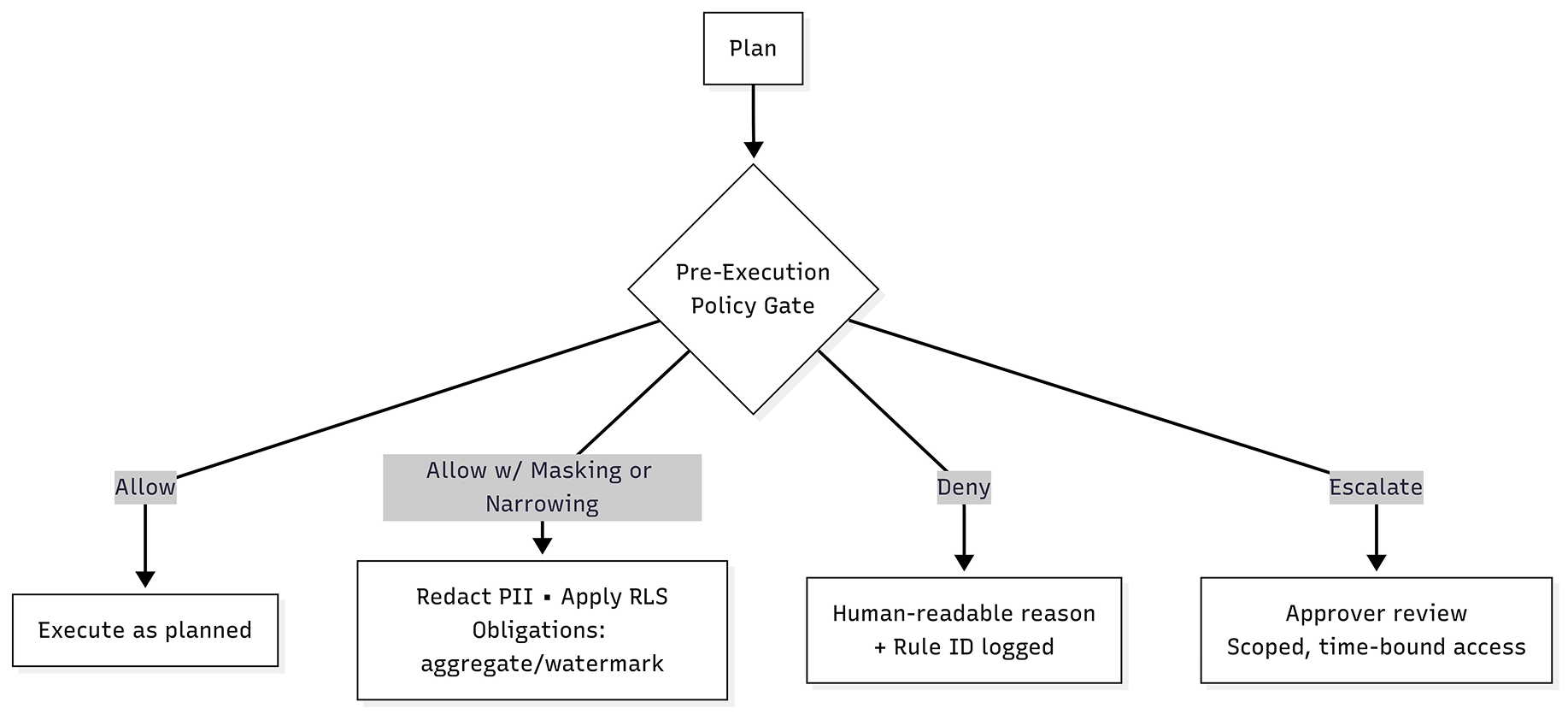
Policies must be enforced. A pre-execution gate sits between planning and data actions. It evaluates who is asking, what they can see, and what the plan intends to do, then decides to:
Allow as requested. The request passes policy checks for role, purpose, sensitivity, and budget. The query executes exactly as planned with full fidelity. We log the "allow" decision and context for audit.
Allow with masking or narrowing. The request is permitted only if sensitive columns are redacted and/or row-level filters are applied. Obligations like aggregation or watermarking may also be enforced. We record exactly what was masked or filtered and why.
Deny with a clear reason. The request violates policy—such as disallowed attributes, excessive scope, or missing consent—so nothing runs. The user gets a human-readable denial message. The rule ID and triggering attributes are logged for audit.
Escalate for approval. The request is risky or exceptional and requires a human decision. An approver reviews the context and can grant limited-time, scoped access or reject it. The final decision and approver details are tied to the run.
Because this gate sits in the query path, every surface and lane inherits the same enforcement. It's one place to prove row filters were applied and one place to inspect denied calls—exactly what auditors expect. 86% of organizations require infrastructure upgrades to support such comprehensive governance frameworks.
Framework #2 — Graph-based planning & orchestration (plans you can see and budget)
Linear prompt chains are opaque. Governed systems need plans you can point at. We orchestrate each request as a graph-style plan. Every step is explicit. Every input and guardrail is visible.

Intent & follow-up handling. We detect whether the question depends on earlier context. Vague phrases like "that" or "same period" are resolved to concrete entities, dates, and filters. The result is a stable, replayable intent even when the wording is informal.
Clarification (only when necessary). If there is a blocking ambiguity, we ask one targeted question. "Sales" may mean revenue or units; we confirm the intended meaning. Out-of-the-box models achieve only ~61% F1 score on ambiguity detection, while approaches like STaR-GATE that learn to ask clarifying questions achieve 72% user preference over baseline models. Documented defaults (for example, fiscal vs. calendar) are applied and disclosed. Optional refinements are offered but do not block execution.
F1 score balances two things: precision (when the model says “ambiguous,” how often it’s right) and recall (of all true ambiguities, how many it actually catches). So ~61% F1 on ambiguity means it misses a lot of real ambiguities and over-flags some that aren’t.
STaR-GATE is a training method where the model learns to ask one short clarifying question before answering when it’s unsure. It practices this via feedback (self-play + human preference), so it prefers asking a targeted question over guessing.
Routing decision. The planner selects a lane based on complexity, semantic confidence, and latency/cost budgets. SRL is chosen for simple governed asks. Text-to-SQL is chosen for complex logic. The choice and the reason are recorded for audit.
Generation & checks. Tellius builds the analysis as semantic roles or schema-aware SQL. Inline checks validate joins, metric–dimension pairs, and safe limits on rows and scans. Disallowed operations are rejected before anything runs.
Execution in the governed query layer. All plans execute through a single policy-enforced layer. Row-level controls and PII masking are applied at the source. Results include a compact policy footprint that shows filters and redactions.
Result assembly & explanation. The final answer includes the context needed to trust it. We show metric definitions, time windows, key steps, clarifications, and any fallbacks due to budgets or safeguards. Users see both the outcome and the rationale.
A graph plan also acts as a control surface. Budgets and timeouts are attached per node. Critique and verification loops are added exactly where they help. A detailed trace explains each decision and duration so you can debug issues and defend results later.
Context engineering > agent count. Most failures come from broken context, not weak models. Sub-tasks often drop important details. Parallel branches can make conflicting choices. Retries may blend old and new state. Fix the context first. Normalize references and defaults at the start of the run. Encode domain rules in the plan, such as allowed joins, valid grains, and fiscal versus calendar time. Carry a single context object through every step and version any change. When you do this, answers remain explainable, reproducible, and consistent across runs.
Framework #3 — Semantics & governed data access (One truth, executed at the source)

Trust collapses when different parts of the system use different definitions. A governed semantic layer removes that risk by fixing shared meaning across the stack.
What the semantic layer defines
Metrics and calculations. Each metric has one approved formula and scope. For example, "Revenue" specifies inclusions, exclusions, time grain, currency, and rounding.
Dimensions and hierarchies. Dimensional attributes are named, typed, and ordered. A Region → Territory → Account hierarchy is explicit and versioned.
Allowed pairings and grains. The model lists which metrics can appear with which dimensions and at what time grain. Illegal pairs are rejected before planning proceeds. Organizations report 40-60% improvement in schema-aware query generation through such structured semantic approaches.
Synonyms and phrasing. Business nicknames and common variants are mapped to canonical terms. Natural language like "top customers" resolves to a governed metric and rank rule.
Lineage and versioning. Every definition records its source, owners, change history, and effective dates. Consumers can see what changed, when, and why.
Two practical patterns that make this work
Phrase Learnings and Query Learnings. Tellius captures how real users speak and how recurring questions should be parsed. Over time, "my area" reliably resolves to the user's region, and "growth QoQ" selects the correct windowed comparison.
Pushdown execution. Heavy computation runs in your warehouse or lakehouse. Row-level policies and masking apply at the source, and both SRL and Text-to-SQL respect the same definitions. There are no shadow copies and no forked business logic.
Modern Text-to-SQL patterns that hold up
Scope the schema before generation. Use metadata and domain signals to reduce the visible tables and columns to the few that matter for the question. This cuts noise and speeds planning. Schema awareness remains the most challenging problem, with production databases often containing hundreds of tables that exceed LLM context windows.
Decompose complex asks. Break requests with nested filters, window functions, or multi-entity joins into clear sub-intents. Recompose them under the semantic contract so each step stays valid.
Refine and validate the candidate SQL. Check join paths, grains, filters, and allowed metric–dimension pairs before execution. Reject unsafe or out-of-policy operations early. Arctic-Text2SQL-R1 from Snowflake demonstrates that execution-based training can enable 7B models to outperform GPT-4o with 95x fewer parameters by focusing on "what works" rather than "what looks correct".
Evaluate by execution and result shape. Treat generated SQL like code. Compare results to a small, trusted golden set and look for schema, row-count, ordering, keyset, or value mismatches.
What this buys you
You eliminate "That's not our revenue!" moments because the system uses one definition everywhere. You reduce misparses because the language the business uses is learned and tied to canonical terms. You deliver consistent answers across chat, search, and notebooks because both lanes execute against the same governed semantics at the source. Despite the complexity, systems achieve 90%+ performance improvements on complex tasks when properly implemented.
Framework #4 — Retrieval & memory without "Vector Dumpsters"
Indexing everything and hoping similarity search finds the right context drowns an agent in noise. For analytics, precision beats volume.
Treat the knowledge graph as governed metadata. Model entities, measures, dimensions, synonyms, and types as first-class objects. Use this metadata to steer interpretation and retrieval before any embedding search. It narrows candidates to what is actually valid for the question.
Keep memory tightly scoped. Bind memory to the current business entities and the active semantic context. An account question should not pull in old product notes. Expire or partition memories so context stays relevant to the run at hand.
Constrain vector search by design. If you use embeddings, fence them with namespaces and filters, and apply TTLs so stale items naturally age out. Re-rank results with structural signals (entity, metric, grain) to avoid long-lived "junk drawer" behavior.
Tie every retrieved artifact to the Business View in play. Record which view, entity, and metric justified its inclusion, and show that rationale in the trace. If you cannot explain why an item was retrieved, it should not influence the answer.
Framework #5 — Clarification, visible reasoning, and evaluation
Clarification (before execution). When the system detects low confidence or multiple possible meanings, it asks one targeted question to remove the ambiguity. It applies safe defaults such as "last 12 months" when appropriate and clearly discloses them. Clarification is minimal and only blocks when necessary. 51% of AI interactions currently use "AI-first assistance" patterns, while only 5% achieve true AI-guided dialogic engagement—clarification bridges this gap.
Visible reasoning (after execution). Every answer includes a short "what we did" summary. It lists the metric definitions used, the exact time window, the major steps taken, and any guardrails or fallbacks that affected the result. Users see both the outcome and the rationale.
Evaluation (always on). Treat generated SQL like code and keep a continuous test loop.
- Stabilize new NL intents. Run them multiple times, check for consistent plans/results, and require passing tests before promotion.
- Compare candidate SQL to a golden. Execute both queries and diff schema and results with sensible tolerances.
- Categorize mismatches. Label issues as schema, row count, ordering, keyset, or values, and route fixes to learnings/prompts/semantics.
- Record a trace for every run. Capture plan ID, model versions, policy decisions, cache state, and timings so you can reproduce or diff later.
This process keeps quality high without telling users to "prompt harder." When properly designed, these systems achieve up to 90% reduction in research time through concurrent agent operations.
Observability and the "Governed Answer Receipt"
If you can't trace an answer, you can't defend it. Each run emits a compact answer receipt with:
The question and any clarifications asked/answered. We record the exact user question in plain text. If you are asked a clarifying question, we capture both the question and the user's answer so reviewers can see how ambiguity was resolved.
The plan ID and lane (SRL or Text-to-SQL), plus the reason. Each run gets a unique plan identifier and a flag for the chosen lane. We also store a short reason (e.g., "multi-join and window function → Text-to-SQL") to justify the routing.
The definitions and time window used. We note the metric and dimension definitions active at run time, including their versions. The exact time window is recorded with start/end timestamps and calendar type.
A policy footprint (e.g., row-level controls enforced; masked columns). The receipt lists which policies were applied, such as row filters or column masking. It also shows any obligations triggered, like aggregation or watermarks.
High-level steps and any fallbacks. We summarize the major steps in the plan so readers understand the path to the answer. If we used a fallback—like a summarized view due to budget limits—we call that out explicitly.
Latency and cost markers. Per-stage timings and total duration are included so you can spot slow hops. We also log token usage or compute estimates to monitor cost per answer. 68% of enterprises budget $500k+ annually on AI agent initiatives, making cost tracking essential.
A trace reference for full lineage. The receipt links to a detailed trace you can open for step-by-step lineage. That trace is the source of truth for deeper audits and debugging.
This is where "preamble" and "reflection" live for users, and where they look first to investigate.

Constraints we acknowledge—and how we mitigate them
Multi-agent loops. They can parallelize work, but they're hard to control and audit. A single central plan with selective branching keeps state consistent, makes retries predictable, and simplifies governance.
Local models. They work well for narrow, scoped tasks with stable tools and short chains. For long, tool-heavy workflows, hosted higher-accuracy models still win on reliability and tail latency.
Schema linking. Over-pruning hides needed columns; under-scoping floods the model. Limit by domain, then validate joins and grains against governed pairings to prevent silent semantic errors.
Benchmarks vs. reality. Passing an NL2SQL benchmark only proves the SQL runs. Business correctness requires enforcing semantics, policy, and consistency across rephrasings, not just execution success.
None of these are "free," but they preserve the powerful lane's benefits without weakening governance or clarity. Organizations achieving 35% cost reduction do so through auto-scaling, spot instances, and strategic resource management—not by cutting corners on governance.
A quick litmus test: What "Best Framework" really means?
Ask five questions of any governed multi-agent framework:
Policy. Where is the pre-execution gate, and what attributes does it check? Can you prove allow/deny/mask decisions per run?
Planning. Can you see the plan graph, attach budgets/timeouts, and pinpoint critique/verification?
Semantics & access. Is there one metric contract, executed at the source under the same rules for every surface and lane?
Retrieval & memory. Is context scoped by entities and governed metadata, not an unbounded vector dump?
Verification & transparency. Can the system clarify before execution, show its reasoning, and evaluate generation quality over time?
Ask less, decide more: Users don't want a quiz; they want a good decision. Detect ambiguity, ask one targeted question, then remember the choice (scoped to user/team/org with a timeout) so you don't re-ask. Disclose safe defaults ("last 12 months; fiscal calendar"). Track two KPIs: how often you ask, and whether asking measurably improves correctness.
Frameworks that answer those five survive audits and daily usage.
One last thing: We handle the guardrails so you can handle the decisions.
Leaders want faster decisions, fewer dashboards, and answers that explain themselves. The only way to meet that bar at scale is to engineer for governance from day one: policy gates before action, plan graphs you can budget and debug, a single semantic contract, scoped retrieval and memory, and verification loops that make quality visible. We do that, and our agents won't just pass demos—they'll pass deployments.
You shouldn't assemble this yourself. The hybrid router, the governed query layer, the semantic contracts, clarification and explanation patterns, and the evaluation harness—that's all backend work. Your experience should be asking business questions and getting fast, trustworthy, explained answers.
Tellius is committed to delivering hassle-free agentic analytics where we handle orchestration, guardrails, and optimization under the hood, and you enjoy deep, insightful answers to every business question—with the receipts to prove it. If you want to see governed agentic analytics under real constraints, we'll walk through live questions, show the receipts, and talk SLOs.
Get release updates delivered straight to your inbox.
No spam—we hate it as much as you do!

%20(14).png)
Beyond Toy Demos: How Tellius Makes AI Analytics Work at Enterprise Scale
Many AI-analytics demos promise magic: impressive visuals, slick dashboards, and smooth interactions. But in real business settings, those polished demos often break down. This post pulls back the curtain and explains what it really takes to make AI analytics work at enterprise scale. You'll learn about: Building agentic architecture that supports complex queries and multi-step insights Ensuring reliability with intent parsing, root cause detection, and strong validation layers Managing data quality, security, and governance so insights can be trusted Scaling models, visualizations, and workflows to support thousands of users and billions of rows of data If you're evaluating AI analytics tools or planning your own build, this is your guide to separating real capabilities from toy demos and focusing on what drives measurable performance.

AI Agents: Transforming Data Analytics Through Agentic AI
AI agents aren’t just hype—they’re the engine behind the next generation of self-service analytics. This post breaks down how agentic AI enables multi-step, contextual analysis workflows that automate the grunt work of business intelligence. Learn what makes agentic systems different, what to look for in a true AI-native platform, and how Tellius is pioneering this transformation.
%20(32).png)
10 Battle Scars from Building Agentic AI Analytics
This blog dives into the practical challenges (“battle scars”) encountered while moving agentic AI analytics from demo to production. Covering real-world engineering and product lessons, it highlights pitfalls like ambiguous language, mismatched definitions, performance tail‑latency, lack of observability, and unreliable multi‑step logic. For each scar, it provides strategies—governed semantics, demander/validator separation, deterministic planning, explicit feedback loops, and transparency—that help build robust, trustworthy analytics agents at enterprise scale. If you’re rolling out AI analytics agents, these lessons can help you avoid common traps and ship with confidence.