Gone are the days where all the data a company wants to analyze comes from a single relational database. In today’s world, most companies have data stored in not only different sources but a variety of different types of sources, from relational databases, NoSQL stores, Hadoop repositories, as well as application sources.
As data sources keep growing and evolving, reconciling data across these disparate resources becomes a considerable challenge. Each of these sources have different storage engines, schema types, and interaction protocols. Providing analytics and actionable intelligence using data across sources is highly valuable but challenging.

Written by: Madhukara Phatak,
at Tellius
In This Post
The Need for Multiple Data Sources
Different storage systems provide different data storage capabilities, and so it is natural for an organization to choose the best tool for the specific application or problem at hand.
Let’s take an example of e-commerce website. The typical data architecture contains the following components:
- Relational databases are used to hold product details and customer transactions.
- Big data warehousing tools like Hadoop/Hive/Impala are used to store historical transactions and ratings for analytics. This reduces the pressure on relational databases.
- Google Analytics to analyze the behavior of customers on the website.
- Log data on S3 or Azure blob storage.
In this example, the organization is using different data systems which are optimized to store the different kind of data.
The Need for Multi-Source Data Analysis
To derive the maximum value from data, an organization typically wants to complete view that connects all the different sources of data. In our e-commerce example, it will be good to combine Google analytics data with transactional data in databases to understand the patterns in users interest.
This kind of multi-source data analysis drives greater value by providing a more complete view compared to single source analysis which will only give one perspective of the overall story.
The Problem With Traditional Multi-Source Data Analysis
Traditionally, multi-source data analysis needed all the data to be moved to single data warehouse. This data warehouse could be a relational database such as Oracle or Teradata, or it could be a big data store such as Hadoop. But these types of systems require costly ETL operations to move the data.
The primary reasons for this ETL is to normalize the data from different sources, and simply to have common storage for running analytics across multi-source data.
This movement of data often result in slowness in analysis. Also, the ETL process creates latency from when data is updated at the original source until new data makes its way into the analytical systems, so the latest data is not always available. For many organizations, they end up performing incomplete data analysis from either fewer sources or delayed data, even though they have access to much more data.
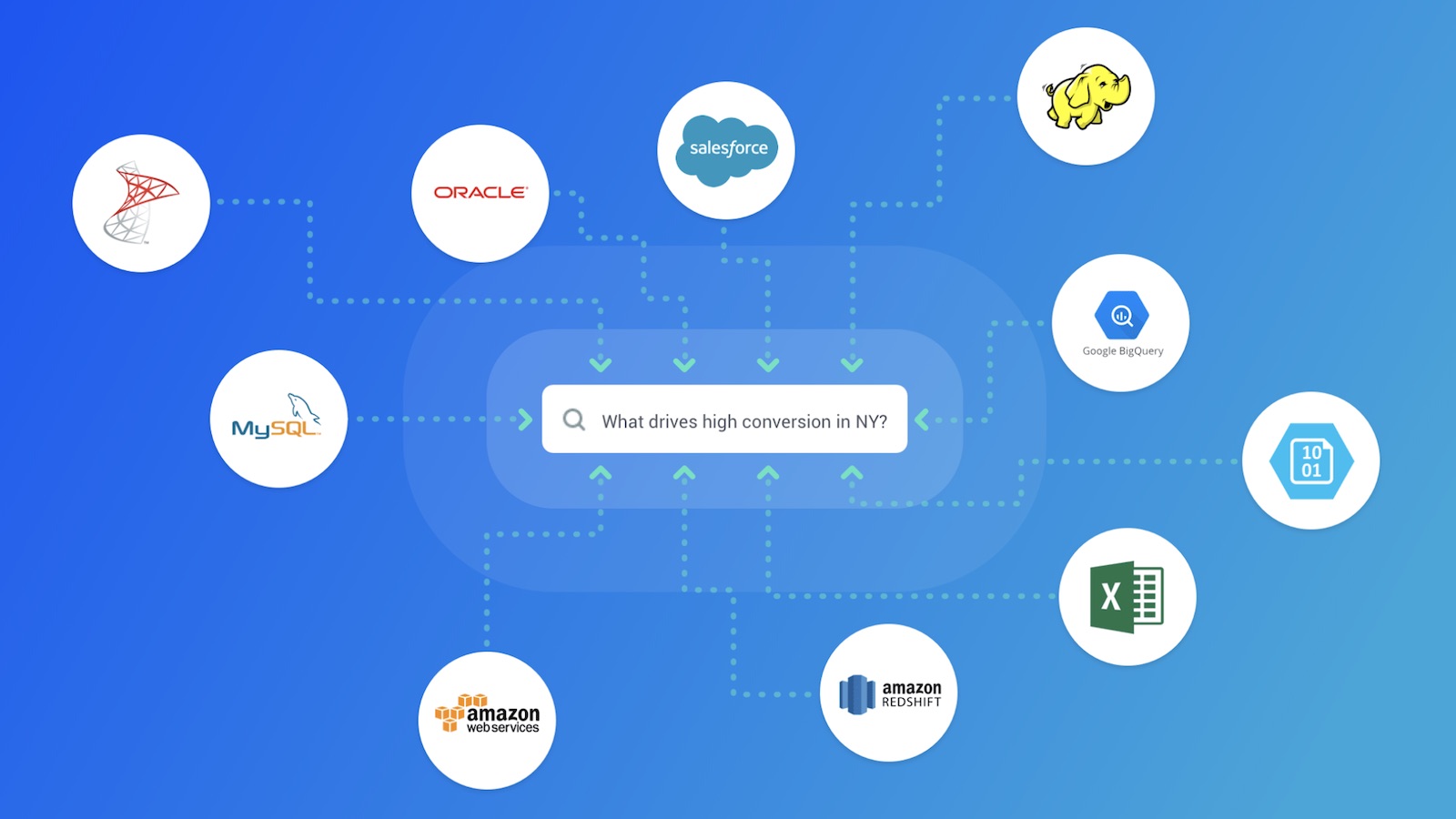
Multi Source Data Support in Tellius

The picture above shows many of the popular connectors supported in the Tellius platform. Tellius can connect to multiple sources and perform multi-source analysis without requiring complete movement of the data. One question we are often asked is: how do we support a seamless search-driven analytics experience across multiple data sources?
Structured Data Analysis for Big Data
Before Apache Spark became popular, it was assumed that “big data” is meant for unstructured data. But in reality, that is not true. From our experience, many of the customers who are big data (and certainly for non-big data customers), most of their data is structured or semi-structured. So any data processing platform we choose has to support structured data processing out of the box.
Apache Spark is the first major big data processing platform which has embraced structured data analysis as native abstraction. This abstraction can support structured, semi-structured, and even unstructured data. Being structured-first allows Spark to combine data from sources such as relational databases, Google analytics, and MongoDB seamlessly. Even for unstructured data, Spark has capabilities to turn that into structured data.
Multi-Source Data Analysis in Spark
From Spark 2.0, Spark has chosen Dataset/DataFrame abstraction, which is built for structured data. This normalizes data read from different sources to a single DataFrame abstraction. This native abstraction combined with Spark SQL gives us the ability to seamlessly unify the data across different sources and make the available for search-driven query and analytics.
Spark loads only the needed data on-demand from the sources. This allows analysis to be done in an ad hoc manner rather than waiting for complete movement of the data in the traditional way. This greatly speeds up the time of analysis.
Natural Language Query on Spark
All the datasets loaded in Tellius are represented as Dataframes on Spark. This gives us the ability to provide an intuitive search experience to the user, where he/she can ask query across different sources with a single question. The queries initiated by the user are internally represented as SparkSQL queries, which then accesses the data across sources. This analysis can use the latest data without the need to make a copy of data in a warehouse system.
Conclusion
Combining the Tellius Search Engine with the versatile Spark engine allows our customers to ask questions of their data irrespective of where the data comes from. This capability gives our customers clear advantages over their traditional systems as they now can leverage all their organizational data for analysis to make better informed decisions.



